Analytische desktop tools
Analytische desktop tools kunnen omschreven worden als een nieuwe generatie van rapporteringtools. Ze weven een transparante laag over de database structuur en bieden zo diverse ad hoc analyse mogelijkheden vanaf de desktop.Ad hoc
Hoewel het gebruik van een analytische desktop tool wegens het risico op performantieproblemen niet aangewezen is op OLTP-niveau, komt het in een gestructureerde informatieomgeving tot zijn volle recht. We kunnen zelfs stellen dat de informatieomgeving aan belang verliest bij het ontbreken ervan.Bij een ODS zou men nog enigszins het nut ervan kunnen aanvechten, gezien de operationele aard van een dergelijke omgeving. Daar de datahoeveelheid op zich echter beperkt is vervalt de belangrijkste reden om er geen gebruik van te maken. De allerbeste aanwending ligt niettemin in de benadering van een dimensionaal datamodel). De symantic layer van dergelijke toepassingen maakt gebruik van zogenaamde objecten, waarbij elk object in theorie overeen komt met een kolom in een databasetabel. Bij het bouwen van de layer kan men dus in zekere zin het sterschema van een data warehouse overnemen en dezelfde logica 1 op 1 implementeren. Binnen de objectstructuur kunnen facts en dimensies apart gepresenteerd worden en kan de business user als het ware binnenkijken in de database, zij het op een gebruiksvriendelijke manier.
Om dit te verduidelijken nemen we even het voorbeeld van een opzet binnen de Business Objects tool. De symantic layer wordt binnen deze software een universe genoemd. De figuur illustreert hoe de business user de database structuur van een financiële data warehouse gepresenteerd kan krijgen.
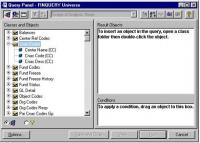 Business Objects voorbeeld - universe
Business Objects voorbeeld - universeDe figuur geeft een beeld van het resultaat van een query die samengesteld werd op basis van deze universe. In de linkerzijde van het scherm worden de result objects weergegeven, in de rechterzijde ziet men de eigenlijke informatie.
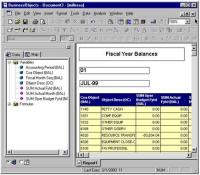 Business Objects voorbeeld - resultaat
Business Objects voorbeeld - resultaatData Cube
Een van de belangrijkste kenmerken van een goede analysetool is de aanwezigheid van een interne data cube, die de geëxtraheerde data intern zal stockeren voor verder gebruik binnen de toepassing. In functie van het aantal geselecteerde dimensies kan het gaan over een eendimensionale tot een multi-dimensionale cube. Aangezien quasi elke rapport toch minimum gebruikt maakt van een gewone dimensie en een tijdsdimensie kunnen we ervan uit gaan dat we steeds te maken hebben met het tweede scenario.Het voordeel van de data cube is de scheiding van extractie en gebruik. Zo kan een rapport gescheduled worden om s nacht de interne kubus met een grote hoeveelheid data op te vullen, zodat s morgens meteen gebruik kan gemaakt worden van deze data om een representatief rapport te bouwen. Zoals wel vaker het geval is, is dit voordeel meteen ook het grootste nadeel. Doordat de data intern opgeslagen wordt binnen een rapport dat lokaal gestockeerd wordt op het filesysteem, vindt er als het ware een transformatie plaats van centrale data in lokale data. Indien er niet op regelmatige basis een refresh gebeurt van de gegevens binnen de lokale cube, bestaat de kans dat er op een gegeven ogenblik een inconsistentie ontstaat tussen de data in de data warehouse en deze binnen het rapport.
Men merkt bij een data cube dat de structuur enigszins overeen komt met deze van een MOLAP-cube, met dit verschil dat de MOLAP-cube zich centraal op de database bevindt en de data cube een lokaal gegeven is.
Web analysis tools
Met het internet is de wereld kleiner geworden en is de nood gegroeid aan tools die op elk ogenblik en vanaf elke locatie de nodige informatie kunnen weergeven. Vandaar ook dat de meeste desktop tools tegenwoordig voorzien in een web-based equivalent. Men staat soms wat sceptisch tegenover de neiging die bepaalde vendors hebben om elke functionaliteit van hun desktop tool ook in een webtoepassing te voorzien. Het veroorzaakt een nodeloze complexiteit en een verlies aan werkingskracht binnen een platform dat hiervoor niet bestemd is.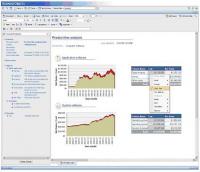 Business Objects voorbeeld - web
Business Objects voorbeeld - web© 2010 - 2025 Andyv, het auteursrecht van dit artikel ligt bij de infoteur. Zonder toestemming is vermenigvuldiging verboden. Per 2021 gaat InfoNu verder als archief, artikelen worden nog maar beperkt geactualiseerd.
 CAT tools: hulp voor vertalersCAT (Computer Aided Translation) tools zijn computerprogramma's die het werk van vertalers een stuk gemakkelijker maken.…
CAT tools: hulp voor vertalersCAT (Computer Aided Translation) tools zijn computerprogramma's die het werk van vertalers een stuk gemakkelijker maken.…
Gerelateerde artikelen
Operational BI toolsEen schitterende informatieomgeving op zich heeft weinig nut indien men niet beschikt over de praktische mogelijkheden o…
Boze mensen maken betere beslissingenLange tijd werd boosheid gezien als een emotie die nadelige effecten op beslissingen en informatieverwerking heeft. Er w…
Extraction, Transformation & Loading (ETL)Om data te onttrekken uit een operationele omgeving en deze op een informatieve wijze te hermodeleren in een fysisch ged…
Hoe haal je als ondernemer meer omzet?De economie kent haar hoogtepunten en dieptepunten. Een ondernemer probeert natuurlijk zich in te dekken voor de dieptep…
Dashboard en Balanced ScorecardDashboards en Balance Scorecards worden gebouwd om kaderleden de mogelijkheid te bieden om in een oogwenk de situatie va…
Bronnen en referenties
- Business Intelligence Kring (http://www.bi-kring.nl/bi-kring)
- Business Intelligence Knowledge Base (http://businessintelligence.ittoolbox.com)
- Business Intelligence (http://www.business-intelligence.co.uk/)
Andyv (19 artikelen)
Laatste update: 16-09-2010
Rubriek: Zakelijk
Subrubriek: Onderneming
Bronnen en referenties: 3
Laatste update: 16-09-2010
Rubriek: Zakelijk
Subrubriek: Onderneming
Bronnen en referenties: 3
Per 2021 gaat InfoNu verder als archief. Het grote aanbod van artikelen blijft beschikbaar maar er worden geen nieuwe artikelen meer gepubliceerd en nog maar beperkt geactualiseerd, daardoor kunnen artikelen op bepaalde punten verouderd zijn. Reacties plaatsen bij artikelen is niet meer mogelijk.