Data Mining binnen een informatieomgeving
Een begrip dat heel vaak genoemd wordt wanneer men het over Business Intelligence heeft is Data Mining. Het gaat gepaard met andere aspecten als cleansing en verrijking van data en is door zijn complexiteit een van de moeilijker te begrijpen termen binnen de BI. Een opheldering is op zijn plaats.Speurtocht
Data mining kan omschreven worden als een speurtocht naar nuttige informatie binnen een bestaande database, met de bedoeling kennis te verwerven. In de literatuur wordt data mining dan ook vaak Knowledge Discovery in Database (KDD) genoemd. Naast de pure kennisverrijking omvat KDD tevens het opschonen of cleansen van bestanden, en de verrijking van de data met zinvolle informatie. Data mining sluit in zekere mate aan bij de HOLAP-techniek (zie artikel Online Analytical Processing (OLAP)) omdat men ook hier vanuit een bepaald standpunt vertrekt en de informatie naar beneden toe zoekt. Maar hoewel data mining zich vooral toespitst op dimensionale data, kunnen sommige situaties vragen om de informatie te zoeken op een veel lager niveau, zoals op het niveau van de ad hoc desktop analysis (zie artikel Ad hoc desktop analysis) of zelfs tot op het niveau van de operationele rapportering (zie artikel Operational Querying).In theorie start het KDD-proces bij de bouw van een data warehouse, gevolgd door kennisextractie en logische interpretatie. In tegenstelling tot de klassieke bouw van een data warehouse, die gebaseerd is op de gegevens en de voorstelling van specifieke business processen, wordt een data warehouse die bedoeld is voor data mining eerder gebouwd vanuit een strategisch oogpunt. We kunnen stellen dat algemene data warehousing een globaal doel voor ogen heeft, terwijl bij data mining eerder gepoogd wordt om een heel specifieke doelstelling te bereiken.
CRM
De meest voorkomende toepassing van data mining is de bouw van een CRM data warehouse. CRM staat voor Customer Relation Management en laat toe een centrale klantendatabase te onderhouden die toegankelijk is voor alle geïnteresseerden binnen de onderneming. Ze garandeert het bestaan van een uniek record voor elke klant binnen de ondernemingsstructuur en biedt volledige en getrouwe informatie die te allen tijde up to date gehouden wordt. Om de uniekheid van de gegevens te kunnen garanderen wordt bij elke aanlevering van klantgegevens gebruik gemaakt van zogenaamde ontdubbelingsprocedures. Op basis van de aangeleverde adresgegevens wordt bepaald of een klant al dan niet in het systeem aanwezig is en of zijn gegevens al dan niet verrijkt dienen te worden met extra informatie. De ontdubbelingsprocedures omvatten vaak complexe algoritmes, die rekening houden met spelling, fonetische klanken en aanverwanten. Een CRM data warehouse is dus zeker niet zomaar in een lijn te brengen met de traditionele data warehouse en wordt dan ook zelden in deze zin benaderd.Externe data & cleansing
Niet alle data vindt zijn oorsprong binnen de onderneming. Dit is zeker het geval bij de CRM materie en dan vooral bij grote bedrijven. Een klantendatabase op zich heeft een standaardmodel met een vaste structuur voor de opname van ondermeer adressen en telefoonnummers. Vandaar dat heel vaak overgegaan wordt tot de aankoop van databestanden die adresinformatie bevatten met betrekking tot bepaalde doelgroepen. Door de diversiteit aan informatiebronnen spreekt het voor zich dat de bestanden onderling zelden of nooit dezelfde fysische structuur zullen hebben. De gebruikte velden voldoen in de meeste gevallen wel aan het standaardmodel, maar veelal bestaat er een inconsistentie doorheen de detailstructuur. We denken onder andere aan de volgorde van de velden of aan een overtolligheid of tekort aan informatie. Naast de gestructureerde data binnen de database zal men dus geconfronteerd worden met diverse vormen van niet-gestructureerde data, die op een correcte manier hun weg zullen moeten vinden binnen het systeem. Dit betekent niet dat de relationele klantgegevens die hun oorsprong vinden binnen de onderneming reeds perfect gestructureerd zijn voor het gebruik binnen een CRM data warehouse. Ook deze gegevens zullen in de meeste gevallen een cleansing- en/of een verrijkingsprocedure moeten doorlopen. Relationele klantgegevens worden dus als het ware samengevoegd met externe data en als een geheel omgevormd tot bruikbare, correcte en vervolledigde data.Toepassing: mailings
Het uiteindelijke gebruik van grote hoeveelheden klantgegevens situeert zich meestal in de marketingomgeving, waar de aangekochte adressen vaak de basis vormen voor het versturen van publicitaire mailings. Om de kostprijs van het mailingproces zo laag mogelijk te houden en een professionele communicatie te onderhouden met de klanten, is het essentieel dat een bepaalde verzending slechts een enkele maal verstuurd wordt naar een bepaald adres. Vandaar dat de ontdubbelingsprocedures een van de belangrijkste aspecten vormen binnen het volledige traject van opladen tot gebruik. Deze vorm van data mining botst in zijn eerste fase enigszins met de algemene definitie, die stelt dat er aan kennis dient ingewonnen te worden om als dusdanig beschouwd te worden. Bij mailingprocessen volgt deze kennis meestal in een later stadium, in functie van de reacties op de mailings. Een gegroepeerde evaluatie van de reacties wijst meestal op interessegebieden en leidt op zijn beurt tot hypotheses die als basis kunnen dienen voor verder onderzoek. Er ontstaat een cataloog van duizenden diverse denkpatronen, die met klassieke analysemiddelen onmogelijk kan bekomen worden. Men kan dus stellen dat bij elke resultaatsanalyse van een mailing aan kennis ingewonnen wordt.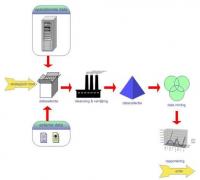 Figuur 1: data mining
Figuur 1: data miningToepassing: evaluatie kijkcijfers
Een ander voorbeeld van data mining is de evaluatie van kijkcijfers bij een televisieproductiebedrijf. Kijkcijfers zijn in zeker mate vergelijkbaar met de resultaten van een enquête, zij het dan dat het product in deze situatie reeds verkocht is. Een evaluatie van de kijkcijfers heeft onherroepelijk een invloed op de programmatie omdat ze het interessepatroon van de kijkers aantonen. Het verleden zal dus de toekomst in de goede richting sturen.Figuur 1 illustreert hoe een data mining beheersflow er in algemene lijnen uitziet. Er wordt vertrokken van een strategisch doel, dat uiteindelijk zal leiden tot acties, gebaseerd op kennis die verworven werd vanuit de verstrekte informatie.
© 2010 - 2024 Andyv, het auteursrecht van dit artikel ligt bij de infoteur. Zonder toestemming is vermenigvuldiging verboden. Per 2021 gaat InfoNu verder als archief, artikelen worden nog maar beperkt geactualiseerd.
 Business intelligenceBusiness Intelligence is een zeer breed toegepast proces waarbij door het verzamelen van bedrijfsgegevens, informatie wo…
Business intelligenceBusiness Intelligence is een zeer breed toegepast proces waarbij door het verzamelen van bedrijfsgegevens, informatie wo…
 Data mining: data verzamelen met web scraping & APIsData is in steeds grotere getale beschikbaar door de komst van het internet. In verschillende branches begint data een b…
Data mining: data verzamelen met web scraping & APIsData is in steeds grotere getale beschikbaar door de komst van het internet. In verschillende branches begint data een b…
 Bitcoins minen: wat heeft u nodig?De bitcoin is een nieuwe virtuele munteenheid die snel in waarde is gestegen. De munt wordt niet gemaakt door overheden…
Bitcoins minen: wat heeft u nodig?De bitcoin is een nieuwe virtuele munteenheid die snel in waarde is gestegen. De munt wordt niet gemaakt door overheden…
Gerelateerde artikelen
Archivering in een informatieomgevingMet de groei van een onderneming groei het aantal beschikbare data en op een gegeven ogenblik ontstaat de nood om te arc…
Dashboard en Balanced ScorecardDashboards en Balance Scorecards worden gebouwd om kaderleden de mogelijkheid te bieden om in een oogwenk de situatie va…
Online Analytical Processing (OLAP)Een gestructureerde informatieomgeving kan moeilijk bestaan zonder gebruik te maken van de OLAP-principes. Maar wat is O…
Bronnen en referenties
- Business Intelligence Kring (http://www.bi-kring.nl/bi-kring)
- Business Intelligence Knowledge Base (http://businessintelligence.ittoolbox.com)
- Business Intelligence (http://www.business-intelligence.co.uk/)
Andyv (19 artikelen)
Laatste update: 16-09-2010
Rubriek: Zakelijk
Subrubriek: Onderneming
Bronnen en referenties: 3
Laatste update: 16-09-2010
Rubriek: Zakelijk
Subrubriek: Onderneming
Bronnen en referenties: 3
Per 2021 gaat InfoNu verder als archief. Het grote aanbod van artikelen blijft beschikbaar maar er worden geen nieuwe artikelen meer gepubliceerd en nog maar beperkt geactualiseerd, daardoor kunnen artikelen op bepaalde punten verouderd zijn. Reacties plaatsen bij artikelen is niet meer mogelijk.